들어가기 전에
해당 글은 다음 글을 번역하였습니다.
https://practica.dev/blog/is-prisma-better-than-your-traditional-orm/
Is Prisma better than your 'traditional' ORM? | Practica.js
Intro - Why discuss yet another ORM (or the man who had a stain on his fancy suite)?
practica.dev
소개: 왜 또 다른 ORM에 대해 이야기할까요?
베터리지의 헤드라인 법칙에 따르면 '물음표로 끝나는 헤드라인은 NO라는 단어로 대답할 수 있다'고 합니다. 이 기사도 이 법칙을 따르게 될까요?
한 우아한 사업가가 멋진 턱시도를 입고 손바닥에 명품 시계를 차고 건물 안으로 걸어 들어오는 모습을 상상해 보세요. 그는 미소를 지으며 손을 흔들며 인사를 건네고 주변 사람들은 감탄사를 연발합니다. 조금 더 가까이 다가가자 충격적이게도 그의 흰 셔츠에 짙은 얼룩이 묻어 있네요. 갑자기 앞의 그 모든 화려함이 얼룩져 버렸습니다.

이 사업가처럼 Node는 뛰어난 성능과 인기를 자랑하지만 특정 분야에서는 열등한 제품으로 얼룩져 있고, 이러한 영역 중 하나가 바로 ORM 분야입니다.
"Java의 'Hibernate'나 .NET의 'Entity Framework'같은 것이 있었으면 좋겠다"는 말은 Node 개발자들이 흔히 하는 말입니다. TypeORM이나 Sequelize와 같은 이미 존재하는 '성숙한' ORM은 어떤가요? 우리는 이것들의 유지보수자들에게 많은 빚을 지고 있지만, 생산된 개발자 경험, 유지 관리 수준은 만족스럽지 않고 심지어 평범하다고 말할 수도 있습니다. 적어도 이 글을 쓰기 전에는 그렇게 생각했습니다...
때때로 반짝이는 새로운 ORM이 출시되고 희망이 생기곤 합니다. 하지만 곧 이 신흥 프로젝트도 살아남게 된다면 결국 비슷비슷하다는 사실을 깨닫게 됩니다. 그러던 어느 날, Prisma ORM이 화려하게 등장했습니다: 엄청난 관심을 받고, 환상적인 콘텐츠를 생산하고, 존경받는 프레임워크에서 사용되고 있으며... 차세대 ORM을 구축하기 위해 40,000,000$(4천만 달러)를 모금했습니다.
Prisma ORM은 우리가 기다려온 '페라리' ORM일까요? 게임 체인저일까요? 만약 당신이 '나에게 맞는 ORM은 없다'는 타입이라면, 이 프로젝트가 당신의 신념을 바꾸게 만들까요?
Practica.js (83000개의 스타를 받은 Node.js 초보자용 베스트 프랙티스 모음집)에서, 우리는 사용자들에게 최고의 판단을 내리도록 도와줍니다. Prisma에 대한 광고에 잠시 들러 이 독특한 제품을 평가하고 우리의 툴박스를 업그레이드해야 할지 결론을 내렸을까요?
이 글은 'ORM 입문서'가 아니라 Prisma가 지향하는 특정 차원에 대한 스포트라이트입니다. 가장 인기 있는 두 Node.js ORM인 TypeORM과 Sequelize와 비교합니다. MikroORM과 같은 다른 경쟁자들은 아직 인기가 많지 않기 때문에, 성숙도는 ORM의 중요한 특성이므로 비교하지 않았습니다.
Prisma가 얼마나 좋은지, 현재 사용 중인 도구를 버려야 할 정도인지 알아볼 준비가 되셨나요?
목차
- 3분만에 Prisma의 기본을 알아보기
- 이것들이 거의 똑같다는 점
- 차별화
- 마무리
3분만에 Prisma의 기본을 알아보기
Prisma에 익숙하지 않은 분들을 위해 전략적인 차이점에 대해 알아보기 전에 Prisma ORM의 워크플로우를 간략하게 소개합니다. 이미 익숙하다면 다음 섹션으로 건너뛰셔도 됩니다.
간단히 말해, Prisma는 ORM 코드를 작동하기 위한 3가지 핵심 단계를 제시합니다.
모델 정의하기
거의 모든 다른 ORM과 달리 Prisma는 데이터베이스-코드 매핑을 모델링하기 위한 고유한 언어(DSL)를 제공합니다. 이 독점적인 구문은 이러한 모델을 TypeScript 제네릭이나 및 장황한 코드가 아니라 최소한의 군더더기로 표현하는 것을 목표로 합니다. 인텔리전스 및 유효성 검사가 걱정되시나요? 잘 만들어진 vscode 확장을 사용하면 됩니다. 다음 예제에서 prisma.schema 파일은 Country 테이블과 일대다 관계를 갖는 Order 테이블이 있는 DB를 설명합니다:
// prisma.schema file
model Order {
id Int @id @default(autoincrement())
userId Int?
paymentTermsInDays Int?
deliveryAddress String? @db.VarChar(255)
country Country @relation(fields: [countryId], references: [id])
countryId Int
}
model Country {
id Int @id @default(autoincrement())
name String @db.VarChar(255)
Order Order[]
}
클라이언트 코드 생성하기
또 다른 특이한 테크닉입니다. ORM 코드를 준비하기 위해, Prisma CLI를 호출해서 다음을 실행해야 합니다.
npx prisma generate
또는 하나의 명령으로 DB를 준비하고 코드를 생성하고 싶다면 다음을 실행하기만 하면 됩니다.
npx prisma migrate deploy
이렇게 하면 나중에 프로덕션 환경에서 실행할 수 있는 마이그레이션 파일과 ORM 클라이언트 코드가 생성됩니다.
이렇게 하면 나중에 프로덕션 환경에서 실행할 수 있는 마이그레이션 파일과 모델에 기반한 TypeScript ORM 코드가 생성됩니다. 생성된 코드 위치는 기본적으로 [root]/NODE_MODULES/.prisma/client 아래에 있습니다. 모델이 변경될 때마다 코드를 다시 생성해야 합니다. 대부분의 ORM은 이 코드를 '리포지토리' 또는 '엔티티' 또는 '활성 레코드'라고 부르지만, 흥미롭게도 Prisma는 이 코드를 '클라이언트'라고 부릅니다. 이것은 나중에 살펴볼 독특한 철학의 일부를 보여줍니다.
클라이언트를 사용해서 DB와 상호작용하기
생성된 클라이언트 코드는 DB와 상호작용하기 위한 다양한 함수와 유형들을 가지고 있습니다. 그저 import해서 사용하면 됩니다.
import { PrismaClient } from '.prisma/client';
const prisma = new PrismaClient();
// 쿼리 예시
await prisma.order.findMany({
where: {
paymentTermsInDays: 30,
},
orderBy: {
id: 'asc',
},
});
// 동일한 클라이언트를 사용해서 CRUD를 할 수 있습니다.
이게 Prisma의 핵심입니다. 다른 ORM들에 비해 달라지고 더 좋아졌나요?
무엇이 똑같나요?
옵션을 비교할 때, 차이점을 설명하기 전에 두 제품 간에 실제로 유사한 점이 무엇인지 설명하는 것이 유용합니다.
다음은 TypeORM, Sequelize 및 Prisma가 모두 지원하는 기능의 일부 목록입니다.
- 정렬, 필터링, 구별, 그룹화 기준, 'upsert'(업데이트 또는 생성) 등이 포함된 일반 쿼리
- 원시 쿼리
- 전체 텍스트 검색
- 모든 유형의 연관/관계(예: 다대다, 자기 연관 등)
- 집계 쿼리
- 페이지네이션
- CLI
- 트랜잭션
- 마이그레이션 및 시딩
- 후크/이벤트(Prisma에서는 미들웨어라고 함)
- 커넥션 풀
- 다양한 커뮤니티 벤치마크 기준, 극적인 성능 차이 없음
- 모두 엄청난 양의 별과 다운로드 수 보유
전반적으로 TypeORM과 Sequelize가 기능이 조금 더 풍부하다는 것을 알았습니다. 예를 들어, 다음과 같은 기능은 Prisma에서만 지원되지 않습니다: GIS 쿼리, DB 수준 사용자 지정 제약 조건(constraint), DB 복제, 소프트 삭제, 캐싱, 쿼리 제외 등.
그럼 이제 두 제품을 실제로 차별화하고 차이를 만드는 요소에 집중해 보겠습니다.
무엇이 근본적으로 다를까요?
전반적인 타입 안전성
TypeScript가 부상한 이후 ORM의 삶은 결코 쉽지 않았습니다. 타입화된 모델과 쿼리 등을 지원해야 하기 때문에 많은 개발자가 땀을 흘리고 있습니다. 예를 들어, Sequelize는 TypeScript 인터페이스를 안정화하는 데 어려움을 겪고 있으며, 현재 3개의 서로 다른 구문과 또 다른 스타일을 제공하는 하나의 외부 라이브러리(sequelize-typescript)를 제공합니다. 아래 구문을 보면 TypeScript용으로 만들어지지 않은 라이브러리를 어떻게든 끼워 넣으려는 사후 고려처럼 느껴집니다. 많은 투자가 이루어졌음에도 불구하고 Sequelize와 TypeORM은 모두 부분적인 타입 안전성만 제공합니다. 간단한 쿼리에서는 타입이 지정된 객체를 반환하지만 attribute/projection과 같은 다른 일반적인 코너 케이스에서는 깨지기 쉬운 문자열이 남게 됩니다. 다음은 몇 가지 예시입니다:
// Sequelize의 성가신 TypeScript interface
type OrderAttributes = {
id: number,
price: number,
// 다른 속성들...
};
type OrderCreationAttributes = Optional<OrderAttributes, 'id'>;
// 😯 문법이 이상하지 않나요?
class Order extends Model<InferAttributes<Order>, InferCreationAttributes<Order>> {
declare id: CreationOptional<number>;
declare price: number;
}// Sequelize의 느슨한 쿼리 타입
await getOrderModel().findAll({
where: { noneExistingField: 'noneExistingValue' } //👍 TypeScript가 이 부분을 경고합니다.
attributes: ['none-existing-field', 'another-imaginary-column'], // 이 컬럼들이 존재하지 않지만 에러를 발생하지 않습니다.
include: 'no-such-table', //😯 이 테이블이 존재하지 않지만 에러를 발생하지 않습니다.
});
await getCountryModel().findByPk('price'); //😯 price 컬럼은 PK가 아니지만 에러를 발생하지 않습니다.// TypeORM의 느슨한 쿼리
const ordersOnSales: Post[] = await orderRepository.find({
where: { onSale: true }, //👍 TypeScript가 이 부분을 경고합니다.
select: ['id', 'price'],
})
console.log(ordersOnSales[0].userId); //😯 'userId'가 반환된 오브젝트의 일부가 아니지만 에러를 발생하지 않습니다.
'Type'ORM이라는 라이브러리가 문자열을 기반으로 쿼리를 수행한다는 것이 아이러니하지 않나요?
Prisma는 어떻게 다른가: Prisma는 완전히 타이핑이 된 프로젝트 별 클라이언트 코드를 생성하는, 완전히 다른 접근법을 취합니다. 이 클라이언트는 모든 쿼리, 연관관계, 하위 쿼리 등 모든 것 (마이그레이션 제외)에 대한 타입을 구현합니다. 다른 ORM은 이산 모델(다른 파일에서 선언된 연관성 포함)에서 타입을 추론하는 데에 어려움을 겪는 반면, Prisma의 오프라인 코드 생성은 더 쉽습니다.
전체 DB 관계를 살펴보고, 사용자 지정 생성 코드를 사용해서 거의 완벽한 Typescript 환경을 구축할 수 있습니다. 왜 '거의' 완벽할까요? 어떤 이유에서인지 Prisma는 마이그레이션에 일반 SQL을 사용하도록 권장합니다. 이로 인해 코드 모델과 DB 스키마 간에 불일치가 발생할 수 있습니다.
그 외에는 Prisma의 클라이언트가 엔드 투 엔드 타입 안전성을 제공하는 방식은 다음과 같습니다.
await prisma.order.findMany({
where: {
noneExistingField: 1, //👍 TypeScript 에러가 발생합니다.
},
select: {
noneExistingRelation: { //👍 TypeScript 에러가 발생합니다.
select: { id: true },
},
noneExistingField: true, //👍 TypeScript 에러가 발생합니다.
},
});
await prisma.order.findUnique({
where: { price: 50 }, //👍 TypeScript 에러가 발생합니다.
});
얼마나 중요한가요: 전반적으로 TypeScript를 지원하는 것은 주로 DX에 유용합니다. 다행히도 저희에게는 또 다른 안전망이 있습니다: 바로 프로젝트 테스트입니다. 테스트는 필수이므로 빌드 시 타입 확인은 중요하지만 생명을 구할 정도는 아닙니다.
Prisma가 잘 하고 있나요: 확실히
SQL을 잊게 만들어줍니다
많은 사람들이 ORM을 피하고 더 낮은 수준의 기술을 사용하여 DB와 상호 작용하는 것을 선호합니다. 이들의 주장 중 하나는 ORM의 효율성에 반대하는 것입니다: 생성된 쿼리를 개발자가 즉시 볼 수 없기 때문에 자신도 모르게 낭비적인 쿼리가 실행될 수 있다는 것입니다. 모든 ORM이 SQL에 대해 구문적 설탕(읽는 사람 또는 작성하는 사람이 편하게 디자인 된 문법)을 제공하지만 추상화 수준에는 미묘한 차이가 있습니다. ORM 구문이 SQL과 유사할수록 개발자가 자신의 작업을 더 잘 이해할 수 있습니다.
예를 들어, TypeORM의 쿼리 빌더는 SQL이 편리한 함수로 쪼개진 것 같습니다.
await createQueryBuilder('order')
.leftJoinAndSelect(
'order.userId',
'order.productId',
'country.name',
'country.id'
)
.getMany();이 코드를 읽는 개발자는 두 테이블 간에 조인 쿼리가 실행될 것이라고 추론할 수 있습니다.
Prisma는 어떻게 다른가: Prisma의 사명은 DB 작업을 간소화하는 것이며, 공식 홈페이지에서는 이렇게 말합니다.
우리는 SQL 베테랑과 데이터베이스를 처음 접하는 개발자 모두 직관적으로 사용할 수 있도록 API를 설계했습니다
데이터베이스 비전문가에게도 어필하고자 하는 야심찬 목표를 가지고 있는 Prisma는 예를 들어 조금 더 추상화된 구문을 구축합니다.
await prisma.order.findMany({
select: {
userId: true,
productId: true,
country: {
select: { name: true, id: true },
},
},
});
여기에서는 join에 대한 알림이 표시되지 않으며 두 개의 관련 테이블(order 및 country)에서 레코드를 가져옵니다. 여기서 어떤 SQL이 생성되고 있는지 짐작할 수 있을까요? 쿼리가 몇 개일까요? 단순 조인을 한 한 개일까요? 놀랍게도, 실제로는 두 개의 쿼리가 생성됩니다. 조인 로직이 DB 내부가 아닌 ORM 클라이언트 측에서 발생하기 때문에 Prisma는 여기서 테이블당 하나의 쿼리를 실행합니다.
DB 카르테시안 조인에서 반복이 많은 경우 관계의 각 측면을 쿼리하는 것이 더 효율적인 경우도 있습니다. 하지만 다른 경우에는 그렇지 않습니다. Prisma는 대부분의 경우 더 나은 성능을 발휘할 것으로 판단되는 것을 임의로 선택했습니다. 제 경우에는 DB 쪽에서 원조인 쿼리를 수행하는 것보다 느리다는 것을 확인했습니다. 개발자로서 저는 고수준 구문(join이 언급되지 않음)으로 인해 이러한 결함을 놓칠 수 있습니다. 제 요점은 Prisma의 달콤하고 간단한 구문은 데이터베이스를 처음 접하고 단시간 내에 작동하는 솔루션을 만드는 것을 목표로 하는 개발자에게는 축복이 될 수 있다는 것입니다. 장기적으로는 DB 상호 작용에 대한 완전한 인식을 갖는 것이 도움이 되며, 다른 ORM은 이러한 인식을 조금 더 장려합니다.
얼마나 중요한가요: 모든 ORM은 사용자에게 SQL 세부 정보를 숨깁니다. 개발자의 인식 없이는 어떤 ORM도 하루를 절약할 수 없습니다.
Prisma가 잘 하고 있나요: 필요하진 않다
성능
ORM 반대론자와 대화하면 일반적으로 합리적인 주장을 들을 수 있습니다: ORM은 '원시' 접근 방식보다 훨씬 느리다는 것입니다. 대부분의 비교에서 원시/쿼리 작성기와 ORM 간의 차이가 무시할 수 없을 정도로 크지 않기 때문에 이는 어느 정도 타당한 관찰입니다.
이는 또한 이러한 벤치마크가 모든 것을 말해 주는 것은 아니며, 모든 솔루션은 원시 쿼리 외에도 원시 데이터를 JS 객체에 매핑하고, 결과를 중첩하고, 타입을 캐스팅하는 등의 매퍼 레이어를 구축해야 합니다. 이 작업은 모든 ORM에 포함되어 있지만 원시 옵션에 대한 벤치마크에는 표시되지 않습니다. 실제로, ORM을 사용하지 않는 모든 팀은 매퍼를 포함한 자체적인 작은 'ORM'을 구축해야 하며, 이는 성능에도 영향을 미칩니다.
Prisma는 어떻게 다른가: 저는 칼로리를 계산하지 않고 ORM 케이크를 먹으며 거의 '원시'에 가까운 쿼리 속도를 달성하는 Prisma를 보면서 마법을 보고 싶었습니다. 이 희망에는 몇 가지 합당하고 논리적인 이유가 있었습니다: Prisma는 Rust로 구축된 DB 클라이언트를 사용합니다. 이론적으로는 객체를 더 빠르게 직렬화하고 중첩할 수 있습니다(실제로는 JS 쪽에서 발생). 또한 처음부터 구축되었기 때문에 수년간 ORM 공간에 축적된 지식을 기반으로 구축할 수 있습니다. 또한, POJO만 반환하므로 ORM 필드로 객체를 꾸미는 데 시간을 낭비할 필요가 없습니다.
이미 알고 계시겠지만, 이 희망은 실현되지 않았습니다. 모든 커뮤니티 벤치마크에서 Prisma는 기껏해야 평균 ORM보다 빠르지 않은 정도입니다. 그 이유는 무엇인가요? 정확히 알 수는 없지만 Go, 향후 언어, MongoDB 및 기타 비관계형 DB를 지원해야 하는 복잡한 시스템 때문일 수 있습니다.
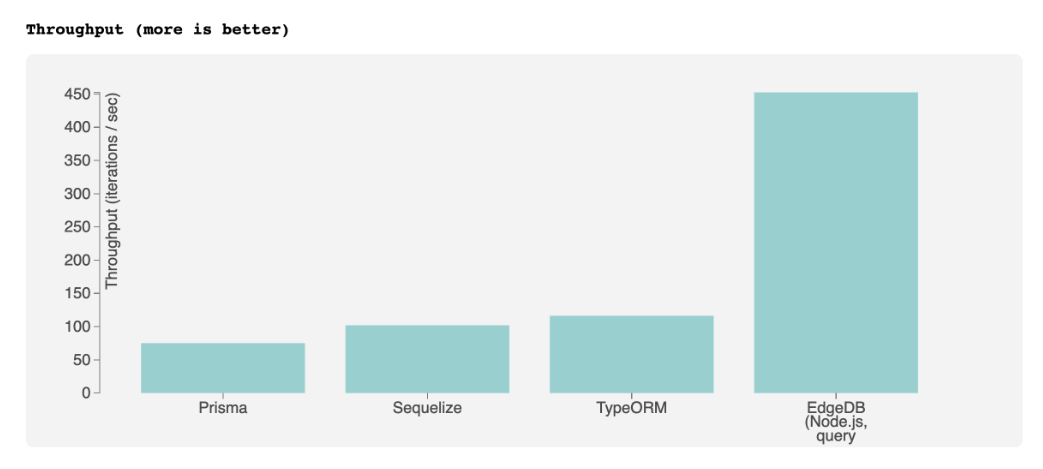
얼마나 중요한가요: 대부분의 시스템에서는 성능 차이가 큰 문제가 되지 않으므로 ORM 사용자들은 열등한 성능에 만족하며 살아갈 것으로 기대합니다. 따라서 다양한 ORM 간의 10~30% 성능 차이는 중요한 요소가 아닙니다.
Prisma가 잘 하고 있나요: 아니요
액티브 레코드 패턴은 안되요
초창기 Node는 Ruby에서 많은 영감을 받았으며(예: 테스트에서 'describe'), 많은 훌륭한 패턴이 수용되었지만 액티브 레코드 패턴은는 성공적인 패턴 중 하나가 아닙니다.
이 패턴은 간단히 말해 무엇일까요? 시스템에서 주문을 처리한다고 가정할 때, 액티브 레코드 패턴을 사용하면 주문 객체/클래스가 엔티티 속성과 일부 로직 함수 및 CRUD 함수를 모두 보유하게 됩니다. 많은 사람들이 이 패턴이 끔찍하다고 생각하는데, 그 이유는 무엇일까요? 이상적으로는 일부 로직/플로우을 코딩할 때 부수 효과와 DB 내러티브에 신경을 쓰지 않아야 합니다. 또한 일부 프로퍼티에 액세스하는 것이 무의식적으로 무거운 DB 호출(즉, 지연 로딩)을 호출할 수도 있습니다.
로직이 무거운 경우에는 단위 테스트가 필요할 수 있습니다(예: '선택적 단위 테스트' 참조). DB와 상호 작용하는 코드에 대해 단위 테스트를 작성하는 것은 훨씬 더 어렵습니다. 사실, 존경받고 널리 사용되는 모든 아키텍처(예: DDD, 클린, 3계층 등)는 시스템의 핵심/로직을 주변 기술로부터 분리하여 '도메인을 분리'하는 것을 지지합니다. 그렇긴 하지만, TypeORM과 Sequelize는 모두 문서 내 많은 예제에 표시된 액티브 레코드 패턴을 지원합니다. 둘 다 데이터 매퍼(아래 참조)와 같은 다른 더 나은 패턴도 지원하지만, 여전히 의심스러운 패턴에 대한 문은 열려 있습니다.
// TypeORM active records 😟
@Entity()
class Order extends BaseEntity {
@PrimaryGeneratedColumn()
id: number
@Column()
price: number
@ManyToOne(() => Product, (product) => product.order)
products: Product[]
// 다른 컬럼들
}
function updateOrder(orderToUpdate: Order){
if(orderToUpdate.price > 100){
// some logic here
orderToUpdate.status = "approval";
orderToUpdate.save();
orderToUpdate.products.forEach((products) =>{
})
orderToUpdate.usedConnection = ?
}
}
Prisma는 어떻게 다른가: 더 나은 대안은 데이터 매퍼 패턴입니다. 이는 간단한 객체 표기법(속성이 있는 도메인 객체)과 DB 언어(일반적으로 SQL) 사이의 다리, 즉 어댑터 역할을 합니다. 일반 JS 객체인 POJO로 호출하고 DB에 저장하면 됩니다. 간단합니다. 결과 객체에 함수를 추가하거나 순수한 데이터를 반환하는 것 외에 다른 작업을 수행하지 않으므로 예상치 못한 부수 효과도 없습니다. 가장 순수한 의미에서 이것은 DB 관련 유틸리티이며 비즈니스 로직과는 완전히 분리되어 있습니다. Sequelize와 TypeORM 모두 이 기능을 지원하지만, Prisma는 이 스타일만 제공하므로 실수할 여지가 없습니다.
// 데이터 매퍼를 사용한 Prisma의 접근법 👍
// Prisma에 의해 자동생성 되었습니다
type Order {
id: number
price: number
products: Product[]
// 다른 컬럼들
}
function updateOrder(orderToUpdate: Order){
if(orderToUpdate.price > 100){
orderToUpdate.status = "approval";
prisma.order.update({ where: { id: orderToUpdate.id }, data: orderToUpdate });
// 부수효과이지만 명시적입니다 👆, 사려 깊은 코더라면 이를 다른 함수로 옮길 것입니다. 외부에서 일어나기 때문에 모킹이 가능합니다. 👍
products.forEach((products) =>{ // 지연 로딩이 아닙니다. 데이터가 이미 존재합니다 👍
})
}
}Practica.js에서는 한 단계 더 나아가 프리즈마 모델을 "DAL" 레이어에 넣고 리포지토리 패턴으로 감쌉니다. 다음은 DAL 계층을 호출하는 비즈니스 흐름입니다.
얼마나 중요한가요: 한편으로 이것은 따라야 할 핵심 아키텍처 원칙이지만, 다른 한편으로는 대부분의 ORM이 이를 올바르게 수행할 수 있도록 허용합니다.
Prisma가 잘 하고 있나요: 네!
문서화와 개발자 경험
TypeORM과 Sequelize 문서는 평범하지만 TypeORM이 조금 더 낫습니다. 제 개인적인 경험에 비추어 볼 때 시간이 지남에 따라 조금씩 나아지고 있지만, 여전히 "좋다" 또는 "훌륭하다"고 할 만한 수준은 아닙니다. 예를 들어, '원시 쿼리'에 대해 알아보고자 하는 경우 Sequelize는 이 문제에 대해 매우 짧은 페이지를 제공하는 반면 TypeORM 정보는 다른 여러 페이지에 분산되어 있습니다. 페이지 매김에 대해 알아보고 싶으신가요? Sequelize 문서를 찾을 수 없습니다. TypeORM에는 150단어로만 구성된 짧은 설명이 있습니다.
Prisma는 어떻게 다른가: 훌륭합니다! 원시 쿼리 및 페이징, 수천 개의 단어, 수십 개의 코드 예제 등 유사한 주제에 대한 문서를 확인하세요. 전문 작가가 참여한 것처럼 느껴질 정도로 글 자체도 훌륭합니다.

얼마나 중요한가요: 훌륭한 문서는 인식을 높이고 함정을 피하는 열쇠입니다.
Prisma가 잘 하고 있나요: 당연하죠
관찰 가능성, 메트릭 및 추적
프로덕션 환경에서 슬로우 쿼리 또는 기타 DB 관련 문제를 진단할 수 있는 좋은 기회(약 99.9%)를 발견할 수 있습니다. 통합 가시성 측면에서 기존 ORM에서 기대할 수 있는 것은 무엇일까요? 대부분 로깅입니다. Sequelize는 쿼리 지속 시간에 대한 로깅과 연결 풀 상태({크기, 사용 가능, 사용 중, 대기 중})에 대한 프로그래밍 방식의 액세스를 모두 제공합니다. TypeORM은 사전 정의된 기간 임계값을 초과하는 쿼리에 대한 로깅만 제공합니다. 이것은 아무것도 없는 것보다는 낫지만, 프로덕션 로그를 연중무휴로 읽지 않는다고 가정하면, 로깅 이상의 기능, 즉 문제가 발생했을 때 경보를 발동하는 기능이 필요할 것입니다. 이를 위해서는 이 정보를 선호하는 모니터링 시스템에 연결할 책임이 있습니다. 로깅의 또 다른 단점은 장황함입니다. 평균 시간만 신경 쓰면 되는데 수많은 정보를 로그에 기록해야 한다는 것입니다. 메트릭은 이러한 목적을 훨씬 더 잘 달성할 수 있으며, 곧 Prisma를 통해 확인할 수 있습니다.
쿼리의 어느 특정 부분이 느린지 자세히 살펴봐야 한다면 어떻게 해야 할까요? 안타깝게도 쿼리 단계별 지속 시간을 세분화할 수 있는 기능은 없습니다.

Prisma는 어떻게 다른가: Prisma는 기업도 타깃으로 하기 때문에 강력한 운영 기능을 제공해야 합니다. 놀랍게도, 이 도구는 메트릭과 개방형 원격 분석 추적을 모두 지원합니다! 메트릭의 경우, 메트릭 키와 값이 포함된 사용자 정의 JSON을 생성하므로 누구나 이를 모든 모니터링 시스템(예: CloudWatch, statsD 등)에 적용할 수 있습니다. 또한, 가장 널리 사용되는 모니터링 플랫폼 중 하나인 Prometheus 형식의 메트릭을 즉시 생성합니다. 예를 들어, prisma_client_queries_duration_histogram_ms 메트릭은 시간 경과에 따른 시스템 내 평균 쿼리 길이를 제공합니다. 더욱 인상적인 것은 오픈 추적에 대한 지원으로, 모든 쿼리의 다양한 단계를 설명하는 스팬을 OpenTelemetry 수집기에 제공합니다. 예를 들어, 쿼리 파이프라인의 병목 현상이 무엇인지 파악하는 데 도움이 될 수 있습니다: 쿼리 파이프라인의 병목 현상이 무엇인지 파악하는 데 도움이 될 수 있습니다.

얼마나 중요한가요: 관찰 가능성이 얼마나 중요한지는 말할 필요도 없지만, 다른 ORM의 공백을 메우는 데는 며칠이 걸리지 않습니다.
Prisma가 잘 하고 있나요: 당연하죠
지속 가능성 - 2024 / 2025년에도 함께 할수 있을까요
우리는 종속성 중 하나가 사라질 위험을 안고 아주 평화롭게 살아갑니다. 하지만 ORM은 바이인(구매)이 더 높고(즉, 대체하기 더 어렵고) 유지 관리가 더 어렵다는 것이 입증되었기 때문에 이러한 위험에 특별한 주의가 필요합니다.
objection.js, waterline, bookshelf과 같이 과거에 성공한 몇 가지 ORM만 봐도 등 존경할 만한 프로젝트는 모두 지난 한 달 동안 커밋이 0건이었습니다. objection.js의 한 명의 유지 관리자는 더 이상 프로젝트를 운영하지 않겠다고 발표했습니다. 이렇게 높은 이탈률은 유지 관리해야 하는 엄청난 양의 움직이는 부품, 수많은 코너 케이스, 그리고 적당한 '예산'으로 운영되는 OSS 프로젝트를 고려할 때 놀라운 일이 아닙니다.
OpenCollective를 보면 Sequelize와 TypeORM은 월 평균 약 1500달러의 자금을 지원받고 있습니다. 이는 5명의 관리자가 매일 스타벅스 카푸치노와 크루아상(6.95$ x 365)을 사먹을 수 있는 금액에 불과합니다. 이 모델과 가장 대조되는 것은 막 시리즈 B를 유치한 스타트업 기업 Prisma가 40,000,000$(4천만)의 자금을 조달하고 80명의 직원을 채용한 것입니다! 이 정도면 지속 가능성에 대한 높은 확신을 가져야 하지 않을까요? 놀랍게도 그 반대가 사실이라고 제안하겠습니다.
오픈소스 ORM은 하나의 큰 고비만 넘기면 되지만, 스타트업 기업은 두 개의 고비를 넘어야 합니다. 오픈소스 프로젝트는 몇 가지 높은 기술 장벽(예: TypeScript 지원, ESM)을 포함하여 임계값을 달성하는 데 어려움을 겪을 것입니다. 이 과정은 보통 몇 년 동안 지속되지만, 일단 임계값을 달성하면 프로젝트는 대부분 유지 관리에 집중하고 위험 영역에서 벗어날 수 있습니다.
TypeORM과 Sequelize에게 좋은 소식은 그들이 이미 그렇게 했다는 것입니다! 두 프로젝트 모두 물 위에서 고개를 들기 위해 고군분투했고, 과거에는 TypeORM이 더 이상 유지보수를 하지 않는다는 소문도 있었지만, 이 고비를 잘 넘겼습니다. 제가 세어보니 두 프로젝트 모두 지난 3년 동안 약 2000건의 PR을 기록했습니다! 리포지토리 트래커를 사용하면 매주 여러 개의 커밋을 볼 수 있습니다. 두 프로젝트 모두 활발하게 움직이고 있으며, ORM에서 기대할 수 있는 대부분의 기능을 갖추고 있습니다. TypeORM은 멀티 데이터 소스 및 캐싱과 같은 기본적인 기능까지 지원합니다. 이제 약속의 땅에 도달한 두 제품이 사라질 가능성은 거의 없습니다. 오픈소스 은하계에서 일어날 수 있는 일이지만, 그 위험은 낮습니다.
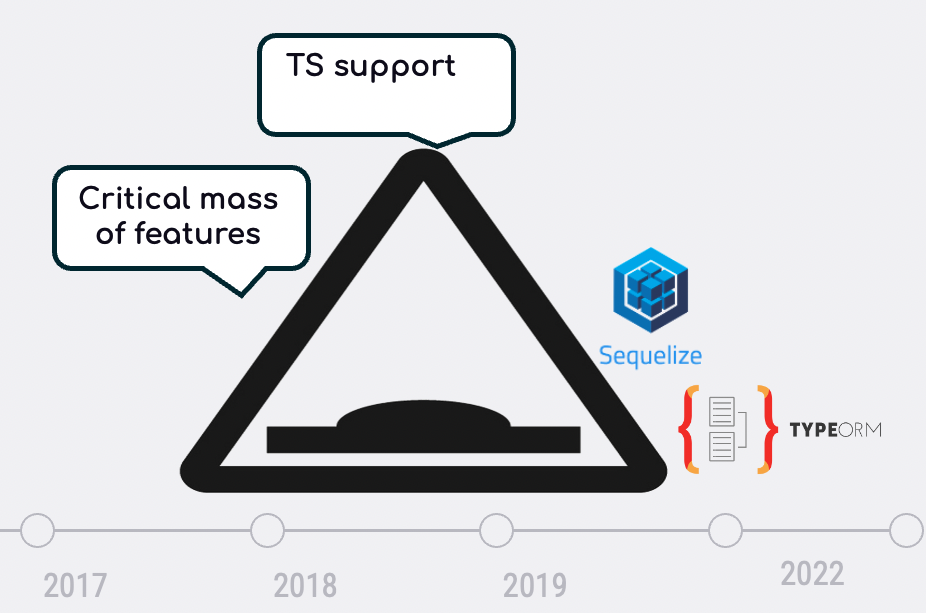
Prisma는 어떻게 다른가: Prisma는 기능면에서 약간 뒤쳐져 있지만 4천만 달러의 예산으로 첫 번째 고비를 통과하여 임계치의 기능을 달성할 것이라고 믿을만한 충분한 이유가 있습니다. 저는 2년 후 수익을 보여주거나 작별 인사를 하는 두 번째 고비가 더 걱정됩니다. 벤처 캐피탈의 지원을 받는 회사로서 다음 라운드인 시리즈 B 또는 C(시드 포함 여부에 따라 다름)를 확보하려면 실행 가능하고 입증된 비즈니스 모델이 있어야 합니다.
ORM은 어떻게 '판매'하나요? Prisma는 여러 제품을 실험하고 있지만 아직 성숙하지 않았거나 유료화되지 않은 제품도 있습니다. 이 위험은 얼마나 클까요? 스타트업 기업의 성공 통계에 따르면 "시리즈 A를 받은 스타트업의 약 65%가 시리즈 B를 받는 반면, 시리즈 A를 받은 기업 중 35%는 실패합니다."라고 합니다. Prisma 이미 커뮤니티에서 많은 사랑과 채택을 받았기 때문에 평균적인 라운드 A/B 기업보다 성공 확률이 높지만, 20% 또는 10%라도 사라질 가능성은 우려됩니다.
충격 뉴스: 기업들은 이 제품이 사라질 확률이 10~30%라는 사실을 깨닫지 못한 채 기꺼이 젊은 상용 오픈소스 제품을 선택합니다.

실행 가능한 비즈니스 모델을 찾는 스타트업 기업 중 일부는 문을 닫지 않고 제품, 라이선스 또는 무료 기능을 변경합니다. 이는 제 주관적인 비즈니스 분석이 아니며, 몇 가지 예를 들어보겠습니다: MongoDB는 라이선스를 변경했고, 이 때문에 대다수가 단일 공급업체를 통해 MongoDB를 호스팅해야 했습니다. Redis도 비슷한 일을 했습니다. Prisma가 다른 유형의 제품으로 전환할 가능성은 어떤가요? 사실 이전에 이미 일어난 일입니다. Prisma 1은 대부분 GraphQL 클라이언트와 서버에 관한 것이었고, 지금은 폐기되었습니다.
다른 잠재적 경로를 언급하는 것은 공평합니다. 대부분의 라운드 B 기업들이 다음 라운드에 진출하는 데 성공하는데, 이 경우 Javascript ORM의 '페라리'를 구축하는 데 더 큰 자금이 투입될 것입니다. 저는 분명히 이 훌륭한 분들을 위해 손가락을 꼬고 있지만, 동시에 우리는 우리의 선택에 대해 의식해야 합니다.
얼마나 중요한가요: 대규모 시스템에서 전체 DB 계층을 다시 코딩해야 하는 것만큼이나 중요합니다.
Prisma가 잘 하고 있나요: 정반대입니다.
마무리 - 지금 무엇을 사용해야 하나요?
주요 ORM이라는 핵심 사항을 제안하기 전에 여기서 소개한 주요 학습 내용을 반복해 보겠습니다:
- 🥇 Prisma는 멋진 DX, 문서화, 통합 가시성 지원, 엔드 투 엔드 TypeScript 지원으로 메달을 받을 자격이 있습니다.
- 🤔 실행 가능한 비즈니스 모델이 없는 신생 스타트업인 Prisma의 비즈니스 연속성에 대해 우려할 만한 이유가 있습니다. 또한 Prisma의 추상적인 클라이언트 구문은 다른 ORM에 비해 개발자의 눈을 멀게 할 수 있습니다.
- 🎩 지난 3년 동안 수천 개의 PR을 병합하여 안정성을 높였고, 새로운 릴리스를 계속 출시하고 있으며(리포지토리 추적기 참조), 현재로서는 Prisma보다 더 많은 기능을 보유하고 있습니다. 또한 둘 다 (ORM치고는) 견고한 성능을 보여줍니다. 유지 관리자들에게 박수를 보냅니다!
이러한 관찰을 바탕으로 어떤 것을 선택해야 할까요? Practica.js에 어떤 ORM을 사용해야 할까요?
Prisma는 Node.js ORM 제품군의 훌륭한 추가 기능이지만, 번거로움 없는 만능 도구는 아닙니다. 여러 가지 맛있는 사탕과 몇 가지 문제점이 섞여 있는 혼합 가방과도 같습니다. 모든 것을 충족하는 도구로 성장하지 않을까요? 그럴 수도 있지만 가능성은 낮습니다. 일단 구축되면 구문과 엔진 성능을 획기적으로 변경하기가 너무 어렵습니다. 하지만 Prisma 애호가를 포함한 커뮤니티와 글을 쓰고 이야기를 나누면서 Prisma가 모든 것을 할 수 있는 '페라리'를 지향하지 않는다는 것을 깨달았습니다. Prisma의 포지셔닝은 탄탄한 엔진과 멋진 사용자 경험을 갖춘 편리한 패밀리 카에 더 가까운 것 같습니다. 즉, 뛰어난 DX, 괜찮은 성능, 비즈니스급 지원에 대한 수요가 대부분인 엔터프라이즈 공간을 겨냥한 것으로 보입니다.
이 여정의 끝에서 저는 지배적인 흠잡을 데 없는 '페라리' ORM을 보지 못했습니다. 관점을 바꿔야 할 것 같습니다: 바쁜 현대 Javascript 생태계를 위한 ORM을 구축하는 것은 2001년 당시 Java ORM을 구축하는 것보다 10배나 더 어렵습니다. 셔츠에 얼룩도 없고 멋진 자바스크립트 스웩입니다. 저는 다양한 기능과 견딜 수 있는 성능, 많은 시스템에서 충분히 사용할 수 있는 현재를 받아들이는 법을 배웠습니다. 더 필요하신가요? ORM을 사용하지 마세요. 극적인 변화는 없을 것이며, 지금이 가장 좋은 상태입니다.
언제 빛을 발할까요?
반드시 Prisma를 사용해야 하는 경우
데이터 요구 사항이 비교적 단순한 경우, 데이터 처리 정확도보다 시장 출시 시간이 더 중요한 경우, DB가 상대적으로 작은 경우, 백엔드 세계에 첫발을 내딛는 모바일/프론트엔드 개발자인 경우, 비즈니스급 지원이 필요한 경우, 프리즈마의 장기적인 비즈니스 연속성 리스크가 문제가 되지 않는 경우 등입니다.
다른 옵션을 추천하는 경우
DB 계층 성능이 주요 관심사인 경우, 탄탄한 SQL 기능을 갖춘 숙련된 백엔드 개발자인 경우, 데이터 계층에 대한 세밀한 제어가 필요한 경우와 같은 조건에서는 다른 옵션을 선호할 수 있습니다. 이 모든 경우에 Prisma가 여전히 작동할 수 있지만, 제가 주로 선택하는 것은 데이터 매퍼 스타일로 knex/TypeORM/Sequelize를 사용하는 것입니다.
결과적으로, 우리는 Prisma를 좋아하며 Practica.js에 플래그(--orm=prisma) 뒤에 추가합니다. 동시에, 일부 클라우드가 사라질 때까지 Sequelize는 기본 ORM으로 유지됩니다.
'라이브러리 프레임워크 > Prisma ORM' 카테고리의 다른 글
| [번역] TypeORM vs Prisma (0) | 2023.07.25 |
|---|---|
| [번역] Prisma는 ORM인가요? (Is Prisma an ORM?) (0) | 2023.07.17 |
